0x01 原因
造个轮子的原因是因为其他的权重查询用着好像不是太友好,总是有些小毛病,漏一个,少一个,结果不对的一些问题,自己就也弄一个,有个缺点就是慢点,优点就是查的比较稳,很少出现结果是n或者漏几个url的问题
0x02 代码
- 主程序代码:
# coding=utf-8
import requests #Author:斯文
import re
import time
from threading import Thread
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
zhanzhang_headers = {
'Host': 'rank.chinaz.com',
'Cache-Control': 'max-age=0',
'Upgrade-Insecure-Requests': '1',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.132 Safari/537.36',
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9',
'Accept-Encoding': 'gzip, deflate',
'Accept-Language': 'zh-CN,zh;q=0.9',
'Cookie': 'BDTUJIAID=febc82b216a29e116730505bc1e471a9; inputbox_urls=%5b%22passivcashincome.com%22%2c%22feifeizuida.com%22%5d; UM_distinctid=16e63892b4e3b1-031b6053dcfc9f-7711b3e-100200-16e63892b4fa8a; Hm_lvt_aecc9715b0f5d5f7f34fba48a3c511d6=1579746706; CNZZDATA433095=cnzz_eid%3D297046501-1578041490-null%26ntime%3D1583974744; CNZZDATA5082706=cnzz_eid%3D902178444-1578044637-null%26ntime%3D1583975389; qHistory=aHR0cDovL3Rvb2wuY2hpbmF6LmNvbV/nq5nplb/lt6Xlhbd8aHR0cDovL3JhbmsuY2hpbmF6LmNvbV/nmb7luqbmnYPph43mn6Xor6J8aHR0cDovL3Rvb2wuY2hpbmF6LmNvbS90b29scy9lc2NhcGUuYXNweF9Fc2NhcGXliqDlr4Yv6Kej5a+GfGh0dHA6Ly93aG9pcy5jaGluYXouY29tL3JldmVyc2UrV2hvaXPlj43mn6V8aHR0cDovL3dob2lzLmNoaW5hei5jb20vK1dob2lz5p+l6K+i',
'Connection': 'close'
}
def process():
print('[+] 正在后台打开谷歌浏览器...')
chrome_option = Options()
chrome_option.add_argument('blink-settings=imagesEnabled=false') #不加载图片, 提升速度
chrome_option.add_argument('--headless') #浏览器不提供可视化页面. linux下如果系统不支持可视化不加这条会启动失败
chrome_option.add_experimental_option('excludeSwitches', ['enable-logging'])#关闭控制台日志,看着太乱
driver=webdriver.Chrome(options=chrome_option)
driver.set_page_load_timeout(5000)
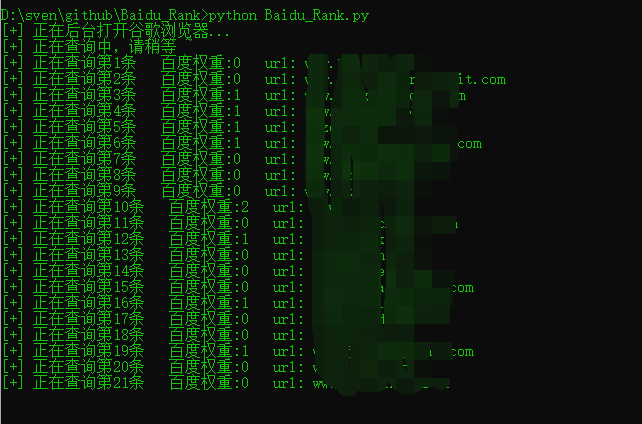
print('[+] 正在查询中,请稍等 ~')
num=0
with open("url.txt") as f:
for line in f:
try:
quanzhong=line.strip('\n')
site=quanzhong.strip('https://')
driver.get('http://rank.chinaz.com/all/{domain}'.format(domain=site))
baidurank_pattern = re.compile(r'csstools.chinaz.com/tools/images/public/baiduapp/(.*?).gif')
try:
html_text = driver.page_source.encode('utf-8')
baidurank = re.findall(baidurank_pattern,html_text.decode('utf-8'))[0]
except:
time.sleep(2.5)
html_text = driver.page_source.encode('utf-8')
baidurank = re.findall(baidurank_pattern,html_text.decode('utf-8'))[0]
num=num+1
print("[+] 正在查询第"+str(num)+"条"+" 百度权重:"+str(baidurank)+" url: "+site)
if int(baidurank) > 0:
with open('seo_1.txt','a',encoding='utf-8') as l:
l.write(site+'\n')
except Exception as e:
pass
driver.close()
0x03 运行
- 1.python3 Baidu_Rank.py 即可
- 2.内置读取同目录的url.txt文件
- 3.权重大于1的网址存入同目录rank_1.txt文件
github链接:https://github.com/sv3nbeast/Baidu_Rank
 支付宝
支付宝  微信
微信